10. システム同定
対象とするシステムのパラメータが未知であるとき、入出力データに基づいてパラメータを同定する。これをシステム同定という。同定法の基本である最小二乗同定は、システムの入力と出力の観測データから、システムのパラメータを推定する手法である。特に、線形離散時間モデルでは、時系列データに基づいてシステムのダイナミクスを推定する際に広く用いられる。
線形離散時間モデルは式(1)で記述される。$$A(q^{-1})y_k = q^{-j}B(q^{-1})u_k + C(q^{-1})e_k \;\;\; \cdots (1)$$ここで、\(y_k\)は出力信号、\(u_k\)は入力信号、\(e_k\)は平均値ゼロの白色雑音である。また、\(A(q^{-1}),\; B(q^{-1}),\; C(q^{-1})\)は、以下で与えられる多項式である。$$A(q^{-1}) = 1 + a_1 q^{-1} + a_2 q^{-2} + \cdots + a_n q^{-n} \\ B(q^{-1}) = b_0 + b_1 q^{-1} + b_2 q^{-2} + \cdots + b_m q^{-m} \\ C(q^{-1}) = 1 + c_1 q^{-1} + c_2 q^{-2} + \cdots + c_l q^{-l} $$式(1)のシステムは、ARMAモデルに\(u_k\)が付加されたもので、CARMA(Controlled Auto-Regressive and Moving Average)モデルという。\(q^{-j}\)は、\(j\)ステップの長さのむだ時間を表している
\(A(q^{-1}), \; B(q^{-1})\)の係数を決定することを考えると、線形離散時間システムは、式(2)のような一般的な 差分方程式 で表される。 $$y_k = a_1 y_{k-1} + a_2 y_{k-2} + \dots + a_n y_{k-n} + b_1 u_{k-1} + b_2 u_{k-2} + \dots + b_m u_{k-m} + \epsilon_k \;\;\; \cdots (2)$$ここで、\(y_k\) : 時刻\(k\)の出力(観測データ)、\(u_k\): 時刻\(k\)の入力(制御信号)、\(a_i\) : 出力の過去データに関する係数(システムの特性を示す)、\(b_j\) : 入力の過去データに関する係数(システムの応答を示す)、\(\epsilon_k\) : ノイズ(観測誤差や外乱)である。
式(2)を行列形式で表すと式(3)となる。この式を基に最小二乗法により、未知のパラメータ \(\theta\)を、誤差の二乗和を最小化するように求める。$$Y = \Phi \theta + \epsilon \;\;\; \cdots (3)$$ここで、
観測データ(出力ベクトル):$$ Y = \begin{bmatrix} y_n & y_{n+1} & \cdots & y_N \end{bmatrix} ^{T}$$回帰行列(説明変数): $$\Phi = \begin{bmatrix} y_{n-1} & y_{n-2} & \dots & y_{n-n} & u_{n-1} & u_{n-2} & \dots & u_{n-m} \\ y_n & y_{n-1} & \dots & y_{n-n+1} & u_n & u_{n-1} & \dots & u_{n-m+1} \\ \vdots & \vdots & \ddots & \vdots & \vdots & \vdots & \ddots & \vdots \\ y_{N-1} & y_{N-2} & \dots & y_{N-n} & u_{N-1} & u_{N-2} & \dots & u_{N-m} \end{bmatrix}$$パラメータベクトル :$$\theta = \begin{bmatrix} a_1 & a_2 & \cdots & a_n & b_1 & b_2 & \cdots & b_m \end{bmatrix}^{T}$$ノイズベクトル:$$\epsilon = \begin{bmatrix} \epsilon_n & \epsilon_{n+1} & \cdots & \epsilon_N \end{bmatrix}^{T}$$である。
この線形回帰モデルにおいて、誤差の二乗和 を最小化するように 最小二乗推定 を適用すると、 $$\hat{\theta} = (\Phi^T \Phi)^{-1} \Phi^T Y$$により、未知パラメータ\(\theta\)を求めることができる。
※最小二乗法に関しては、8-4. 2次形式表現での最小二乗法を参照願います。
Pythonスクリプトでの最小二乗法によるパラメータ推定
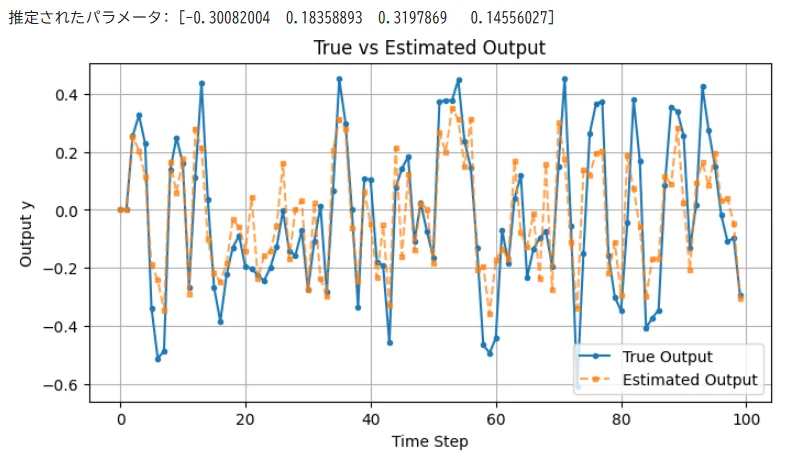
入力\(u_k\)と出力\(y_k\)の時系列データから、未知の係数\(a_i\)と\(b_j\)を求める。図1に実行結果を示す。
#ーーーーーーー Python スクリプト ーーーーーーーー
import numpy as np
import matplotlib.pyplot as plt
# --- 1. シミュレーション用のデータ生成 ---
np.random.seed(42)
N = 100 # データ数
n = 2 # 出力の遅れ次数
m = 2 # 入力の遅れ次数
# 真のシステムのパラメータ(仮定)
true_a = [0.5, -0.2] # yの係数
true_b = [0.3, 0.1] # uの係数
# 入力信号(ランダムなステップ入力)
u = np.random.uniform(-1, 1, N)
# 出力信号(シミュレーション)
y = np.zeros(N)
for k in range(max(n, m), N):
y[k] = true_a[0] * y[k-1] + true_a[1] * y[k-2] + true_b[0] * u[k-1] + true_b[1] * u[k-2] + np.random.normal(0, 0.1)
# --- 2. 回帰行列Φの作成 ---
Phi = []
Y = []
for k in range(max(n, m), N):
row = [-y[k-1], -y[k-2], u[k-1], u[k-2]]
Phi.append(row)
Y.append(y[k])
Phi = np.array(Phi)
Y = np.array(Y)
# --- 3. 最小二乗法によるパラメータ推定 ---
theta_hat = np.linalg.inv(Phi.T @ Phi) @ Phi.T @ Y
print("推定されたパラメータ:", theta_hat)
# --- 4. 推定されたモデルの出力をプロット ---
y_est = np.zeros(N)
for k in range(max(n, m), N):
y_est[k] = theta_hat[0] * y_est[k-1] + theta_hat[1] * y_est[k-2] + theta_hat[2] * u[k-1] + theta_hat[3] * u[k-2]
plt.figure(figsize=(8, 4))
plt.plot(y, label="True Output", linestyle='-', marker='o', markersize=3)
plt.plot(y_est, label="Estimated Output", linestyle='--', marker='s', markersize=3, alpha=0.7)
plt.xlabel("Time Step")
plt.ylabel("Output y")
plt.title("True vs Estimated Output")
plt.legend()
plt.grid()
plt.show()
逐次型最小二乗同定
逐次型最小二乗法(RLS: Recursive Least Squares)は、新しいデータが得られるたびに逐次的にパラメータを更新する手法である。通常の最小二乗法は、すべてのデータを一度に計算する必要があるのに対し、RLSでは計算コストを抑えながらリアルタイムでパラメータを推定できるのが特徴である。
通常の最小二乗法では、以下のような行列表現を解いてパラメータを求める。$$\hat{\theta} = (\Phi^T \Phi)^{-1} \Phi^T Y$$しかし、新しいデータが得られるたびに\(\Phi\)を更新すると、毎回行列の逆行列計算が必要になり計算コストが高くなる。逐次型最小二乗法では、逆行列を直接計算せずに、パラメータを更新する。
新しい観測データ\((y_k, \phi_k)\)が得られたとき、以下の手順で推定パラメータを更新する。
1.誤差の計算$$e_k = y_k - \phi_k^T \hat{\theta}_{k-1}$$
2.ゲイン行列の計算$$K_k = P_{k-1} \phi_k \left( \lambda + \phi_k^T P_{k-1} \phi_k \right)^{-1}$$
3.パラメータの更新$$\hat{\theta}_k = \hat{\theta}_{k-1} + K_k e_k$$
4.共分散行列の更新(パラメータの信頼性を管理)$$P_k = \frac{1}{\lambda} \left( P_{k-1} - K_k \phi_k^T P_{k-1} \right)$$ここで、\(\hat{\theta}_k\):時刻\(k\)におけるパラメータ推定値、\(P_k\):共分散行列(パラメータ推定の信頼性を表す)、\(\phi_k\) :新しい入力データ(回帰ベクトル)、\(y_k\) :新しい観測データ、\(\lambda\):忘却係数(\(0 \lt \lambda \leq 1\))(小さいほど過去のデータの影響が小さくなる)である。
逐次型最小二乗法のメリットとしては、リアルタイム更新可能(新しいデータが得られるたびにパラメータを更新できる。)、計算コストが低い(行列の逆行列計算を逐次的に行うため、大規模データでも処理が速い。)、動的システムに適応可能(システムの特性が時間とともに変化しても、\(\lambda\)(忘却係数)を適切に設定することで対応可能。)などである。
逐次型最小二乗法のPythonスクリプト
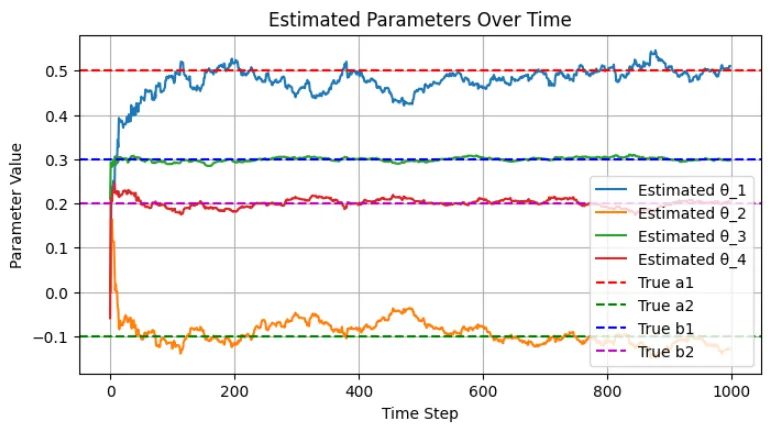
図2に実行結果を示す。時間が経つにつれ、推定値が真のシステムパラメータに収束していくことが確認できる。
# ーーーーーー Pythonスクリプト ーーーーーーー
import numpy as np
import matplotlib.pyplot as plt
# --- 1. シミュレーション用のデータ生成 ---
np.random.seed(42)
N = 1000 # データ数
n = 2 # 出力の遅れ次数
m = 2 # 入力の遅れ次数
# 真のシステムパラメータ(仮定)
true_a = [0.5, -0.1] # yの係数
true_b = [0.3, 0.2] # uの係数
# 入力信号(ランダムなステップ入力)
u = np.random.uniform(-1, 1, N)
# 出力信号(シミュレーション)
y = np.zeros(N)
for k in range(max(n, m), N):
y[k] = true_a[0] * y[k-1] + true_a[1] * y[k-2] + true_b[0] * u[k-1] + true_b[1] * u[k-2] + np.random.normal(0, 0.05)
# --- 2. 逐次型最小二乗法の初期化 ---
theta_hat = np.zeros(n + m) # 初期パラメータ
P = np.eye(n + m) * 10 # 共分散行列(適切な大きさに変更)
lambda_ = 0.99 # 忘却係数を 0.99 に調整(収束を安定化)
# パラメータ推定結果の記録用
theta_history = []
# --- 3. 逐次更新処理 ---
for k in range(max(n, m), N):
phi_k = np.array([y[k-1], y[k-2], u[k-1], u[k-2]]) # 符号を修正
y_k = y[k] # 観測データ
# 逐次更新計算
e_k = y_k - phi_k.T @ theta_hat
K_k = P @ phi_k / (lambda_ + phi_k.T @ P @ phi_k)
theta_hat = theta_hat + K_k * e_k
P = (P - np.outer(K_k, phi_k.T @ P)) / lambda_
# 推定結果の記録
theta_history.append(theta_hat.copy())
# --- 4. 推定結果の可視化 ---
theta_history = np.array(theta_history)
plt.figure(figsize=(8, 4))
for i in range(n + m):
plt.plot(theta_history[:, i], label=f'Estimated θ_{i+1}')
plt.axhline(y=true_a[0], color='r', linestyle='--', label="True a1")
plt.axhline(y=true_a[1], color='g', linestyle='--', label="True a2")
plt.axhline(y=true_b[0], color='b', linestyle='--', label="True b1")
plt.axhline(y=true_b[1], color='m', linestyle='--', label="True b2")
plt.xlabel("Time Step")
plt.ylabel("Parameter Value")
plt.title("Estimated Parameters Over Time")
plt.legend()
plt.grid()
plt.show()