9. ARMAモデル
ARMAモデルは、時系列データを扱うときによく使われるモデルで、データの自己相関やランダムなノイズを考慮して、将来の値を予測するのに役立つ。
ARMAモデルは、以下の2つの要素を組み合わせたモデルである。
・AR(Auto-Regressive, 自己回帰)モデル
・MA(Moving Average, 移動平均)モデル
これらを組み合わせることで、時系列データの現在の値が過去の値とノイズの影響を受けるという現象を表現できる。式(1)で表せる。$$x(t) = c + \sum_{i=1}^{p} a_i x(t-i) + e(t) + \sum_{j=1}^{q} b_j e(t-j) \;\;\; \cdots (1)$$ここで、\(x(t)\):時刻\(t\)の出力値(観測データ)、\(c\):定数項、\(a_i\):AR項の係数、\(b_j\):MA項の係数、\(e(t)\):ホワイトノイズ(平均0、分散一定のランダムな揺らぎ)、\(p\):AR成分の次数、\(q\):MA成分の次数、である。
・AR (自己回帰) モデルは現在のデータが過去のデータの線形結合で決まるモデルである。例えば、AR(1)モデル(1次自己回帰)は$$x(t) = c + a_1 x(t-1) + e(t)$$と表せる。過去の値 \(x(t-1)\)を使って現在の値を決めることになる。
・MA (移動平均) モデルは、現在のデータが過去のノイズの線形結合で決まるモデルである。例えば、MA(1)モデル(1次移動平均)は$$x(t) = c + e(t) + b_1 e(t-1)$$と表せる。これは、今のノイズだけでなく、過去のノイズも影響するモデルである。
ARMAモデルを離散化した形に書き換えると次のようになる。
離散時間ARMAモデルは、自己回帰 (AR) と移動平均 (MA) の2つの要素を組み合わせた時系列モデルであり、離散時間ステップ\(k\)で表すと、一般的なARMAモデルは、$$x_k= c + \sum_{i=1}^{p} a_i x_{k-i} + e_k + \sum_{j=1}^{q} b_j e_{k-j} \;\;\; \cdots (2)$$と記述できる。ここで、\(x_k\):時刻\(k\)の観測データ、\(c\):定数項、\(a_i\):AR項の係数、\(b_j\):MA項の係数、\(e_k\):ホワイトノイズ(平均0、分散一定のランダムな揺らぎ)、\(p\):AR成分の次数(過去のデータの影響範囲)、\(q\):MA成分の次数(過去のノイズの影響範囲)である。
AR(1)(1次自己回帰)モデルは、$$x_k = c + a_1 x_{k-1} + e_k$$と表せ、過去の値\(x_{k-1}\)を利用して現在の値を決めるモデルである。
MA(1)(1次移動平均)モデルは、$$x_k = c + e_k + b_1 e_{k-1}$$と表せ、現在のノイズ \(e_k\)だけでなく、過去のノイズ \(e_{k-1}\)も影響するモデルである。
例えば、ARMA(2,1)モデルは、(AR(2) + MA(1))なので、$$x_k = c + a_1 x_{k-1} + a_2 x_{k-2} + e_k + b_1 e_{k-1}$$で与えられる。これは、過去2ステップのデータと過去1ステップのノイズが現在のデータに影響を与えるモデルとなっている。
最小2乗推定
\(n\)次のARモデルから\(e_k\)を除いた部分を線形予測器とみなし、式(3)で定義する。$$\hat{x}_k = \sum_{i=1}^n a_i x_{k-i} \;\;\; \cdots (3)$$このときの予測誤差は、$$e_k = x_k - \hat{x}_k = x_k - \sum_{i=1}^n a_i x_{k-i}$$となる。ここで、評価関数\(J = E\left[e_k^2\right]\)を最小にする係数\(a_i\)を求めよ。
解答例: 時刻\(k\)がみえるように書くと評価関数は、$$J = \lim_{N \to \infty} \frac{1}{N}\sum_{k=1}^N e_k^2$$と、2乗誤差の平均で表せる。予測誤差の式を評価関数\(J = E\left[e_k^2\right]\)に代入すると、$$J = E\left[\left(x_k - \sum_{i=1}^n a_i x_{k-i}\right)^2\right]$$である。最適な\(a_i\)を求めるために、評価関数\(J\)を \(a_j\)について偏微分してゼロに設定する。$$ \frac{\partial J}{\partial a_j} = E\left[2 \left( x_k - \sum_{i=1}^n a_i x_{k-i} \right)(-x_{k-j}) \right] = 0$$整理すると、 $$E\left[ x_k x_{k-j} \right] = \sum_{i=1}^{n} a_i E\left[x_{k-i} x_{k-j}\right]$$となる。これは Yule-Walker方程式 (自己回帰 (AR) モデルのパラメータを求めるための方程式)である。ここで、自己相関関数\(R(i)\)を\(R(i) = E[x_k x_{k-i}]\)で定義して、上式を行列形式で表すと $$ \begin{bmatrix} R(0) & R(1) & \cdots & R(n-1) \\ R(1) & R(0) & \cdots & R(n-2) \\ \vdots & \vdots & \ddots & \vdots \\ R(n-1) & R(n-2) & \cdots & R(0) \end{bmatrix} \begin{bmatrix} a_1 \\ a_2 \\ \vdots \\ a_n \end{bmatrix} = \begin{bmatrix} R(1) \\ R(2) \\ \vdots \\ R(n) \end{bmatrix}$$となる。よって、係数\(a_i, \; i=1,2,\cdots,n\)は、$$ \begin{bmatrix} a_1 \\ a_2 \\ \vdots \\ a_n \end{bmatrix} = \begin{bmatrix} R(0) & R(1) & \cdots & R(n-1) \\ R(1) & R(0) & \cdots & R(n-2) \\ \vdots & \vdots & \ddots & \vdots \\ R(n-1) & R(n-2) & \cdots & R(0) \end{bmatrix} ^{-1} \begin{bmatrix} R(1) \\ R(2) \\ \vdots \\ R(n) \end{bmatrix}$$で求まる。
Pythonスクリプトによる数値解法
import numpy as np
# 仮の自己相関関数(例: AR(2)の場合)
R = np.array([1.0, 0.8, 0.5]) # R(0), R(1), R(2)
n = len(R) - 1 # AR次数
# 自己相関行列
R_matrix = np.array([[R[abs(i-j)] for j in range(n)] for i in range(n)])
# 右辺ベクトル
b = np.array(R[1:])
# 係数 a_i の解
a = np.linalg.solve(R_matrix, b)
print("最適な係数 a_i:", a)
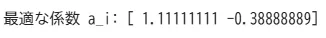
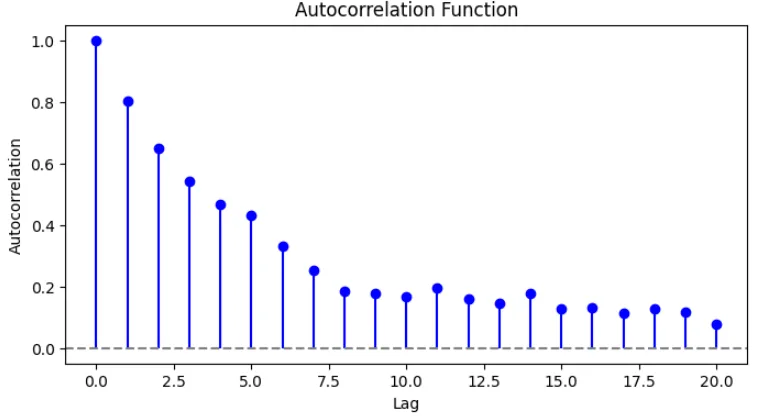
自己相関関数(Autocorrelation Function)
自己相関関数とは、時系列データの異なる時点間での相関 を示す指標である。ある時系列データがどの程度過去のデータと相関を持つかを定量化して、周期性やトレンドを分析するための重要な手法である。
自己相関関数の定義:時系列データ\(x_k\) の自己相関関数\(R(j)\)は、時刻\(k\)のデータと\(k−j\)のデータとの共分散をとり、以下の式で定義する。$$R(j) = E[x_k x_{k-j}]$$特に、標本自己相関関数は、有限長のデータ列\(\{x_1, x_2, ..., x_N\}\)に対して、次のように計算される。$$R(j) = \frac{1}{N} \sum_{k=j+1}^{N} x_k x_{k-j}$$また、自己相関を標準化したもの(自己相関係数)を、$$\rho(j) = \frac{R(j)}{R(0)}$$と表す。
ここで、\(R(0)\)はデータの分散に相当する。
\(\rho(j)\)の値が0に近い場合は、自己相関がない(ランダムな系列)ということになる。
\(\rho(j)\)の値が1に近い場合は、強い自己相関がある(過去の値の影響が強い)ということになる。
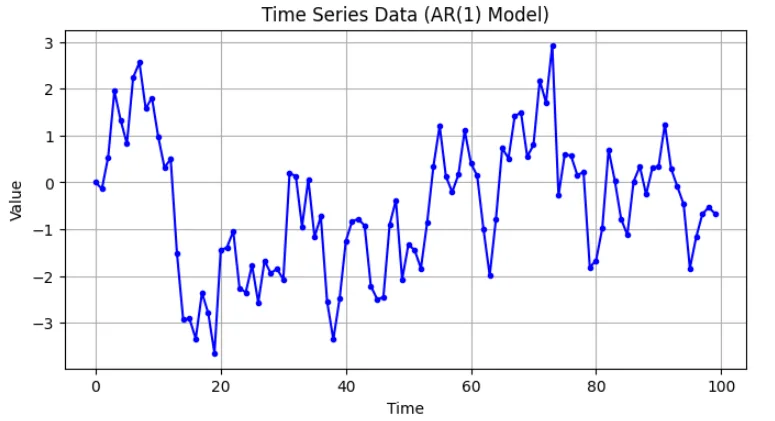
[例]自己回帰モデル AR(1): \(x_k = 0.8 x_{k-1} + \epsilon_k\)(\(\epsilon_k\)はホワイトノイズ)このデータを使って自己相関関数を求める。
Python を使って、自己相関関数を計算しプロットするスクリプトを示す。
import numpy as np
import matplotlib.pyplot as plt
# --- 1. AR(1)モデルのデータ生成 ---
np.random.seed(42) # 再現性のためにシードを固定
N = 100 # サンプル数
alpha = 0.8 # AR(1)の係数
# ホワイトノイズ
epsilon = np.random.normal(0, 1, N)
# AR(1)モデルのデータ生成
x = np.zeros(N)
for k in range(1, N):
x[k] = alpha * x[k-1] + epsilon[k]
# --- 2. 自己相関関数の計算 ---
def autocorrelation(x, max_lag):
N = len(x)
R = np.zeros(max_lag + 1)
for j in range(max_lag + 1):
R[j] = np.sum(x[j:] * x[:N-j]) / N
return R / R[0] # 標準化(自己相関係数)
max_lag = 20 # 最大ラグ
acf = autocorrelation(x, max_lag)
# --- 3. 元の時系列データのプロット ---
plt.figure(figsize=(8, 4))
plt.plot(x, color='blue', linestyle='-', marker='o', markersize=3)
plt.xlabel("Time")
plt.ylabel("Value")
plt.title("Time Series Data (AR(1) Model)")
plt.grid(True)
plt.show()
# --- 4. 自己相関関数のプロット ---
plt.figure(figsize=(8, 4))
markerline, stemlines, baseline = plt.stem(range(max_lag + 1), acf, basefmt=" ")
plt.setp(markerline, color='b', marker='o') # 点の色とマーカー設定
plt.setp(stemlines, color='b', linestyle='-') # ステムの色とスタイル設定
plt.axhline(y=0, color='gray', linestyle='--')
plt.xlabel("Lag")
plt.ylabel("Autocorrelation")
plt.title("Autocorrelation Function")
plt.show()
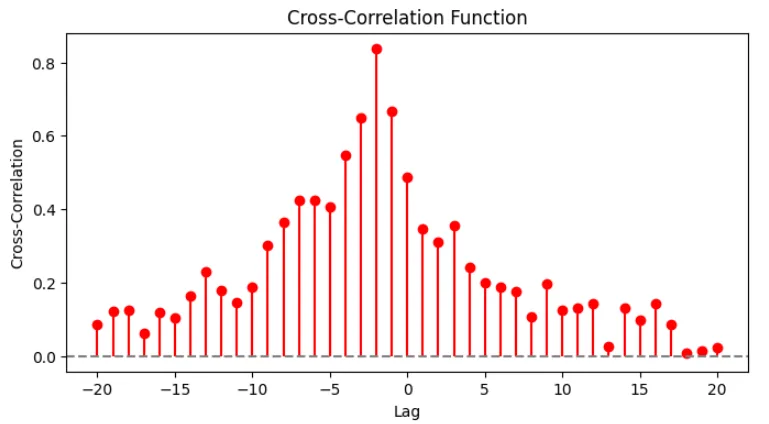
相互相関関数(Cross-Correlation Function)
相互相関関数は、2つの異なる時系列データ間の関係性を測る指標である。これは、ある時系列データ\(x_k\)と別の時系列データ\(y_k\)の時間遅れ(ラグ)による影響を定量化するために使用される。
相互相関関数の定義:2つの時系列データ\(x_k\)と\(y_k\)に対する相互相関関数\(R_{xy}(j)\)は、次のように定義される。$$R_{xy}(j) = E[x_k y_{k-j}]$$これは、\(x_k\)と\(y_{k-j}\)の共分散を計算することに相当する。
標本データを用いる場合、標本相互相関関数 は以下のように計算される。$$R_{xy}(j) = \frac{1}{N} \sum_{k=j+1}^{N} x_k y_{k-j}$$また、これを標準化すると 相互相関係数になる。$$\rho_{xy}(j) = \frac{R_{xy}(j)}{\sqrt{R_{xx}(0) R_{yy}(0)}}$$
\(\rho_{xy}(j)\)の値が0に近い場合は、 2つの系列は独立していることになる。
\(\rho_{xy}(j)\)の値が1に近い場合は、\(x_k\)と\(y_k\)は強く正の相関を持つことになる。
\(\rho_{xy}(j)\)の値が -1 に近い場合は、\(x_k\)と\(y_k\)は強く負の相関を持つことになる。
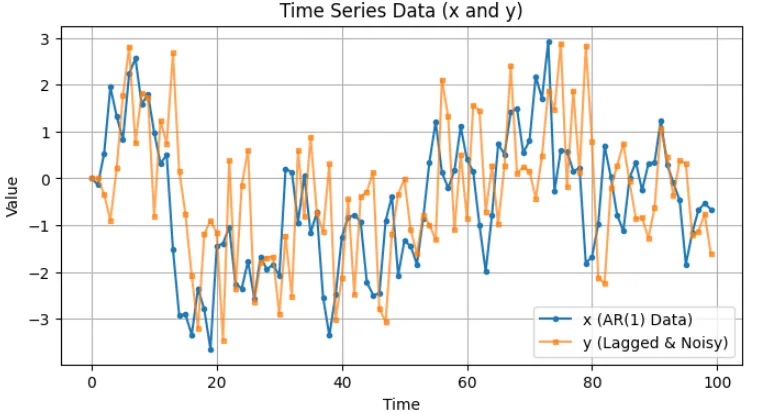
[例]2つの時系列データを考える。データ1:AR(1)モデル(自己回帰係数\(\alpha = 0.8\))、データ2:データ1を遅らせたもの + ノイズとして、\(y_k = \beta x_{k-2} + \eta_k\)とする。\(\beta = 0.7\)とし、\(x_k\)の 2 ステップ遅れが\(y_k\)に影響を与えると仮定する。
Python を使って、相互相関関数を計算しプロットするスクリプトを示す。
import numpy as np
import matplotlib.pyplot as plt
# --- 1. AR(1)モデルのデータ生成 ---
np.random.seed(42) # 再現性のためにシードを固定
N = 100 # サンプル数
alpha = 0.8 # AR(1)の係数
beta = 0.7 # 相互相関の影響係数
lag = 2 # y_k は x_k の2ステップ遅れ
# ホワイトノイズ
epsilon = np.random.normal(0, 1, N)
eta = np.random.normal(0, 1, N) # y_k のノイズ
# AR(1)モデルのデータ生成
x = np.zeros(N)
for k in range(1, N):
x[k] = alpha * x[k-1] + epsilon[k]
# y_k は x_k の2ステップ遅れに影響を受ける
y = np.zeros(N)
for k in range(lag, N):
y[k] = beta * x[k-lag] + eta[k]
# --- 2. 相互相関関数の計算 ---
def cross_correlation(x, y, max_lag):
N = len(x)
R = np.zeros(2 * max_lag + 1)
lags = np.arange(-max_lag, max_lag + 1)
for i, j in enumerate(lags):
if j < 0:
R[i] = np.sum(x[:N+j] * y[-j:]) / N
else:
R[i] = np.sum(x[j:] * y[:N-j]) / N
return R / np.sqrt(np.var(x) * np.var(y)), lags # 標準化(相互相関係数)
max_lag = 20 # 最大ラグ
ccf, lags = cross_correlation(x, y, max_lag)
# --- 3. 元の時系列データのプロット ---
plt.figure(figsize=(8, 4))
plt.plot(x, label='x (AR(1) Data)', linestyle='-', marker='o', markersize=3)
plt.plot(y, label='y (Lagged & Noisy)', linestyle='-', marker='s', markersize=3,
alpha=0.7)
plt.xlabel("Time")
plt.ylabel("Value")
plt.title("Time Series Data (x and y)")
plt.legend()
plt.grid(True)
plt.show()
# --- 4. 相互相関関数のプロット ---
plt.figure(figsize=(8, 4))
markerline, stemlines, baseline = plt.stem(lags, ccf, basefmt=" ")
plt.setp(markerline, color='r', marker='o') # 点の色とマーカー設定
plt.setp(stemlines, color='r', linestyle='-') # ステムの色とスタイル設定
plt.axhline(y=0, color='gray', linestyle='--')
plt.xlabel("Lag")
plt.ylabel("Cross-Correlation")
plt.title("Cross-Correlation Function")
plt.show()